









模型介绍
「日日新V6.5」大模型,凭借率先突破的“图文交错思维链”技术,以及多模态融合强化学习、架构优化等多项创新,在多模态推理与交互性能上表现优异,超越Gemini 2.5 Pro、Claude 4-Sonnet;多模态交互能力超越Gemini 2.5 Flash和GPT-4o。同时,基于模型架构改进,相较日日新6.0性价比可提升3倍以上。

规格介绍
| SenseNova V6.5 Pro 旗舰模型 | SenseNova V6.5 Turbo 高性价比模型 |
支持 on/off 两种思考模式 支持多模输入 32K上下文 | 支持 on/off 两种思考模式 支持多模输入 32K和 128K上下文 |
免费发放千万tokens体验额度!







模型亮点

 领先多模能力
领先多模能力
 图文理解
图文理解
 深度推理
深度推理
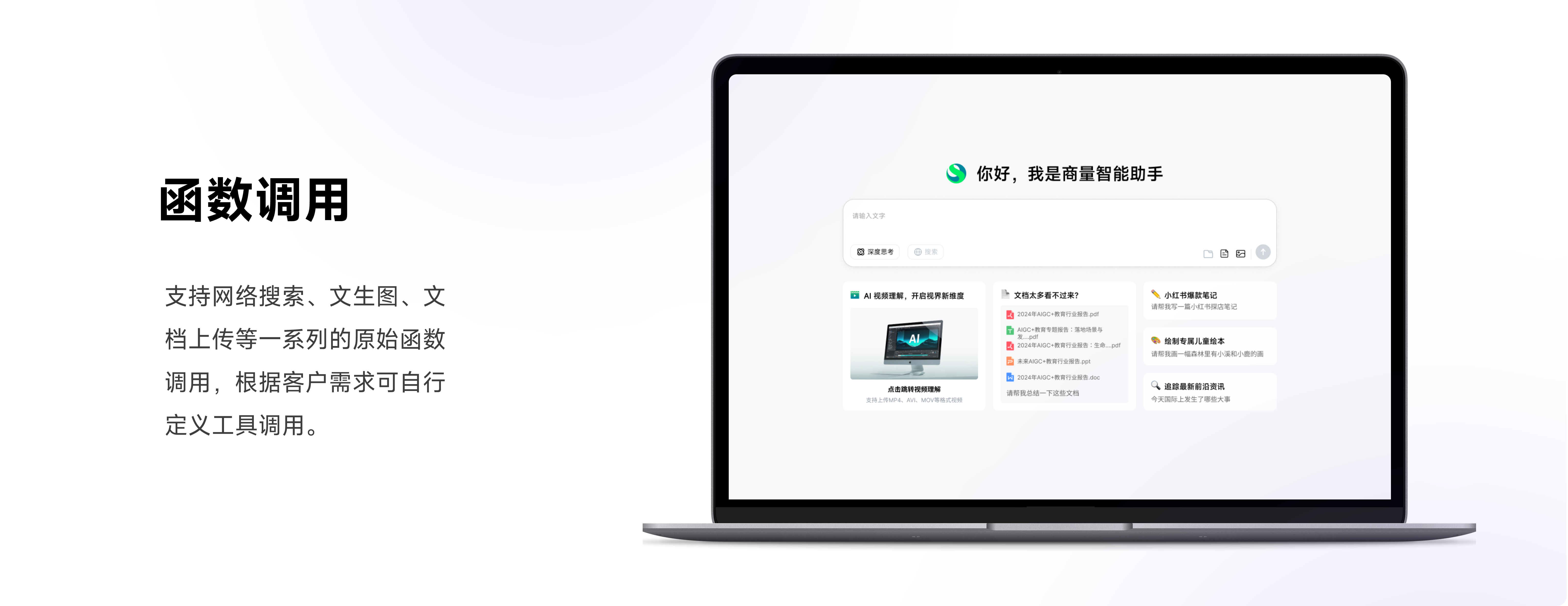
 函数调用
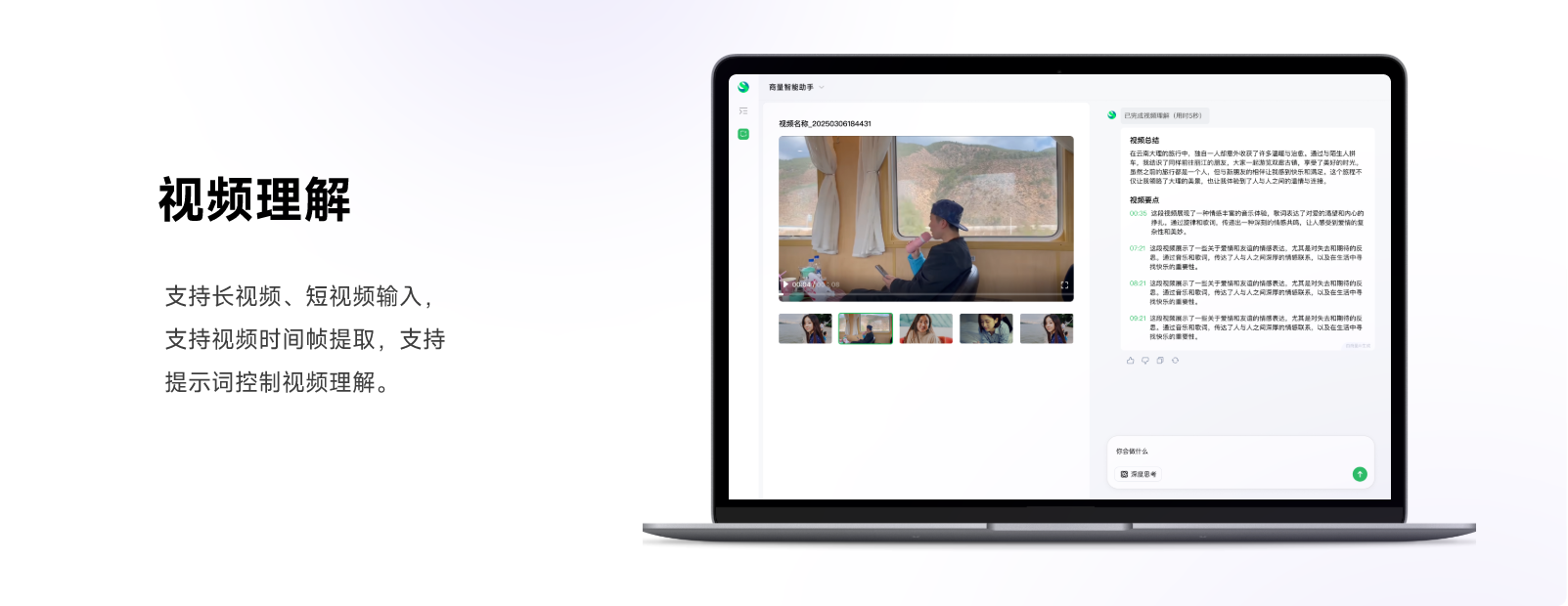
函数调用- 视频理解
- 同时支持语言大模型chat能力、多模态模型VQA问答能力,且在多项测评中获得双冠军

- 支持图片、文本、视频的多模输入,融合多模信号进行推理

- 创新支持基于视觉、文本的慢思考和深度推理,呈现完整的思维链过程,并获得最终推理答案

- 支持网络搜索、文生图、文档上传等一系列的原始函数调用,根据客户需求可自行定义工具调用
- 支持长视频、短视频输入,支持视频时间帧提取,支持提示词控制视频理解
模型优势
在面向多模能力和语言能力领域的多个学术评测和外部榜单的测评中,日日新融合模态大模型在多模基础能力、语言基础能力等核心维度全面领先,文理兼修,在多项测评中多次位列国内外第一梯队水平
多模态推理能力
| V6.5-Pro | V6.5-Turbo | Gemini 2.5 Pro-03-25 | Gemini 2.5 Flash thinking | Claude-4-sonnet-thinking | |
| MathVista | 83.1 | 80.4 | 80.9 | 77.9 | 73.5 |
| DynaMath | 54.29 | 52.5 | 56.3 | 48.5 | 44.91 |
| MathVerse | 73.73 | 69.8 | 76.9 | 70.3 | 57.74 |
| WeMath | 73.05 | 67.24 | 78 | 73.52 | 63.81 |
| MMMU | 76.67 | 72.11 | 74.7 | 74.67 | 79.33 |
| MMStar | 78.33 | 73.8 | 73.6 | 76.20 | 69.53 |
多模态能力横评表
服务优势
- 灵活稳定的API模型服务
通过云服务API的方式提供模型的调用服务,满足多样业务场景需求
- 多模态理解和深度推理
支持高质量的图片、文字、视频输入,具备多模态理解能力,同时具备基于多模态理解的慢思考和深度推理能力,胜任通用和复杂的多模态交互场景。
- 模型推理服务
通过API产品,企业可快速构建自己专属的大模型应用,服务稳定可靠
基于商汤SenseCore大装置强大的AI基础设施,支持专有云部署,满足企业数据安全方面的需求
- 模型落地支持
模型产品团队贴身服务提供提示词工程及工作流调优支持,帮助企业快速完成联调上线正式服务。